John Bradshaw
Daylight CIS Inc., Sheraton House, Castle Park, Cambridge, CB3 0AX, UK
In order to assess the similarity between two molecules A and B we need to first describe the molecules according to some scheme and then choose an appropriate measure to compare the descriptions of the molecules. A common method is to create a binary string where a bit or set of bits being set on implies the presence of a particular feature; see the fingerprint section of the Daylight manual for further details. This process is independent of the measure we may use to associate or compare these binary strings.
If we repeat this process for a large number of molecules we introduce a third independent process of classification or clustering. In general classification assigns a molecule to a class or set of classes on the basis of its similarity to a class prototype. The classes are independent of the set in general and a molecule may be a member of more than one class. This is the appropriate technique for diversity analysis if one is looking for "gaps", say, in one's compound collection. Clustering, on the other hand, is aimed at dividing up, the set, by some algorithm, so that members of a cluster are more similar to each other than they are to members of other clusters. The clusters formed are set dependent. Note that the act of clustering, by its nature, forms "gaps" or "holes" in the chemical space.
If we describe our molecules by the presence or absence of features, then the binary association coefficients or similarity measures are based on the four terms a, b, c, d shown in the two way table.
| OBJECT B | ||||
|---|---|---|---|---|
| 0 | 1 | Totals | ||
| OBJECT A | 0 | d | b | b+ d |
| 1 | a | c | a + c = A | |
| Totals | a + d | b + c = B | n | |
Where
a is the count of bits on in object A but not in object B.
b is the count of bits on in object B but not in object A.
c is the count of the bits on in both object A and object B.
d is the count of the bits off in both object A and object B.
In addition
n = ( a + b + c + d )
A = ( a + c )
B = ( b + c )
where
n is the total number of bits on or off in objects A or
B.
A is the count of the bits on in object A.
B is the count of the bits on in object B.
In the Daylight toolkit
n = dt_fp_nbits()
A = dt_fp_bitcount
(fpA)
B = dt_fp_bitcount
(fpB)
From version 4.8 there will be an additional function
c = dt_fp_commonbitcount(fpA,fpB)
Alternatively the relationship can be viewed as a Venn diagram
There are two major classes of association coefficients.
Pre 4.5 releases of the Daylight software provided an example of each of
these classes.
As both numerator and denominator are functions of d, E belongs to the first class of association coefficients dependent on the double zeros.
In reality the value returned for this coefficient in the toolkit by dt_fp_euclid() is the complement of this, i.e. the Hamming distance, or the Total Difference Coefficient (Sneath, P.H.A., (1968) Journal of General Microbiology 54, 1-11)
T is independent of d, i.e. T belongs to the second class of association coefficients defined above. This is the value returned by dt_fp_tanimoto() It may be regarded as the proportion of the "on-bits" which are shared.
Over the years there has been much discussion as to which type of coefficient to use. In chemistry it has generally been thought that, as most descriptor features are absent in most molecules, i.e. the bit string descriptors such as the Daylight fingerprint contains mainly zeros, coefficients such as the Tanimoto are more appropriate. In version 4.5 Daylight extended the range of coefficients which could be used by introducing the Tversky index. This allowed users to make use of directional similarity and harness the power of the concepts of prototypes in similarity searching.
As has been indicated above all of these indices are not monotonic, and as early as 1982 Hubalek (see Z. Hubalek, Biol. Rev. (1982)57, 669-689) showed that the coefficients could be clustered on the ranking of a given set of objects.
Recently Willett et al In Press have shown that value can be gained from applying the technique of data fusion ( see Ginn, C.M.R., Willett, P., Bradshaw, J., (2000) Perspectives in Drug Discovery and Design 20, 1-16 ) to the rankings of a set of objects using a range of matching coefficients.
What we will provide from version 4.8 are "hard coded" versions of coefficients with different information content, which have a chemically relevant interpretation. In addition we will provide tools which allow users to construct their own coefficients from the values of a, b, c, d, described above. The aim is to allow use of these coefficients anywhere in our applications where similarity coefficients are currently used. I.e the Tanimoto coefficient can be called using the string "Tanimoto" or the string "c/(a + b + c)". Demonstrations of these features are available in xvmerlin() using the program object module in the current release.
Super-structure based matching coefficients.
The concept of super/sub-structure is fundamental to many processes in chemical information. A measure of the similarity between one object and another is the proportion of its features which are shared with the other. This is pursued in detail in the Tversky measure.
For molecule A it is given by
and for molecule B by
It is worth noting that these terms take the form of conditional probabilities see Andeberg M.R. (1973) "Cluster Analysis for Applications" Academic Press, New York, p 91 for details). In brief , c/A is the conditional probability that a random bit is on in B given that it was on in A. The equivalent relationship exists for c/B.
It would not be unreasonable, that the non-directional similarity, between A and B, is the the mean of these two values, i.e. the conditional probability that a bit is set in one molecule given that it is on in the other.
If we take the arithmetic mean, we get the Kulczynski measure ( Kulczynski, S., (1927) Bulletin International de l'Acadamie Polonaise des Sciences et des Lettres, Classe des Sciences Mathématiques et Naturelles, Série B ( Sciences Naturelles), Supplement II 57-203 see also Driver, H.E., Kröber, A.L. (1932) The University of California Publications in American Archaeology and Ethnology 31, 211-256).
0.5*[(c/A) + (c/B)]
If we take the geometric mean, we get the Cosine index ( Driver, H.E., Kröber, A.L. (1932) The University of California Publications in American Archaeology and Ethnology 31, 211-256 see also Ochiai, A (1957) Bulletin of the Japanese Society for Scientific Fisheries 22, 526-530).
sqrt[(c/A) * (c/B)] = c/sqrt(A * B)
Note that the Cosine index is also the geometric mean equivalent of the Dice index ( Dice, L.R., (1945) Ecology 26, 297-302 see also Sørensen, T., (1948) Kongelige Danske Videnskabbernes Selskab, Biologiske Skrifter 5, 1-34).
c/0.5*(A + B)
where, instead of taking the mean of the similarities, we have taken the mean of the number of features in A and B.
In addition to these symmetrical measures there is the related asymmetric Simpson coefficient, ( Simpson, G.G. (1943) American Journal of Science 241, 1-31 )
max{ c/A, c/B ) = c/min(A,B)
where, instead of taking the mean of the similarities, we have taken the maximum of the similarities. This produces some interesting behaviour in clustering.
These four indices form a non-monotonic set, have chemically sensible interpretations and are easily calculated using the toolkit. Note that the Dice index is fully monotonic with Tanimoto.
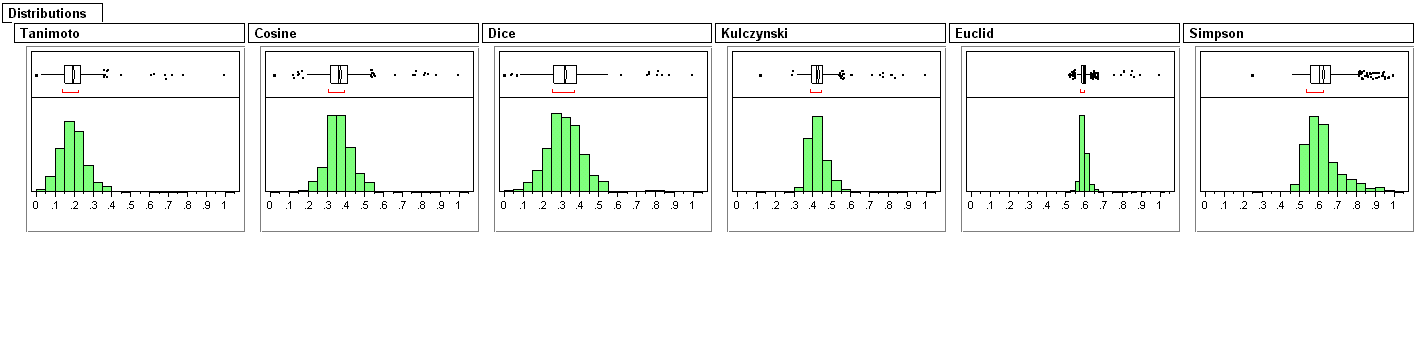
Statistics are reported for a sample of 863 compounds available from Tocris against an arbitrary target for these new measures. Tanimoto and Euclid (matching coefficient ) are included for completeness. In terms of absolute values
Euclid?Simpson >= Cosine >= Dice >= Kulczynski >= Tanimoto
for any pair. They all cover the range 0 -> 1. The correlation coefficients are reported, along with the matched pairs plots.

Quite clearly from these examples, there is extra information in these other measures and it is not unreasonable that a consensus measure could have more discriminating power.
These measures can also be used in searching and clustering. If we choose a non-parametric approach i.e. only use the ranks then there will be differences in near neighbour sets as these measures are not monotonic. If we use a cut-off value, say 0.8, then the proportion of neighbours captured will vary. This is shown well by the histograms for the distribution of values for the various measures.
We will need to make these measures available within the merlin clients ( xvmerlin() and mcl() ), directly from toolkit calls dt_mer_progob_compare() via the same program object and within the clustering package. These functions are even more relevant in DayCart® as we allow users more freedom with fingerprint searches than via the merlin suite.
Daylight Chemical Information
Systems, Inc.
info@daylight.com