
Jack Delany
Introduction:
The Daylight Chemistry cartridge is the result of several distinct collaborative development projects within Oracle, Novartis, Ontogen and Daylight. This whitepaper/presentation will describe Oracle Cartridge technology, review the history of the internal and external projects which have contributed to this effort, describe the current Daylight Cartridge implementation, and provide a view of future direction for the cartridge.
Oracle Cartridge Technology:
An Oracle Data Cartridge is a bundled set of tools which extends Oracle clients and servers with new capabilities. Typically, a single data cartridge deals with a particular 'information domain'. Some examples of current data cartridges include: image processing, spatial processing, audio processing.
A cartridge consists of a number of different components which work together to provide complete database capabilities within the information domain. The components include:
A cartridge extends the server. The new capabilites are tightly integrated with the database engine. The Cartridge interface specification provides interfaces to the query parser, optimizer, indexing engine, etc. Each of these subsystems of the server learns about the cartridge capabilities through these interfaces. The cartridge can use SQL, PL/SQL, Java, C, etc. to implement the functions.
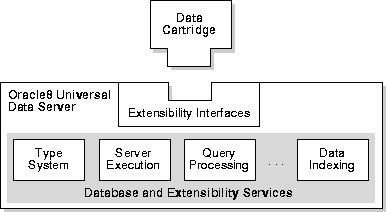
From Oracle's point of view, the cartridge idea allows third-party organizations to expand the capabilities of the Oracle database server in a modular, supportable fashion.
Project History:
In late 1997 - early 1998, two independent projects were undertaken relating to 'alternate database interfaces' to the Daylight system.
Interest generated from Mug98 resulted in an ongoing Daylight / Oracle project to generate requirements, develop a cartridge prototype, and refine its functionality. The paradigm for this version of the cartridge was the "dayblob". Dayblob is a complete set of chemical functions and a merlin-pool-like implementation of chemical searching embedded completely within Oracle. This was most recently discussed in a talk by Dave Weininger during Mug99.
In Spring, 1999, Oracle released Oracle 8i (version 8.1.5), the first production version to support full cartridge capabilities. Version 8.1.6 is projected for general release spring of this year. It will have some notable features which will impact the Daylight cartridge implementation for the long term.
In light of Oracle 8.1.5 and 8.1.6 functionalities and performance issues, we've revisited some of the design constraints related to the Dayblob architecture and have been working on a new architecture for the cartridge.
So, what is the Daylight Cartridge? First, what it isn't. It isn't a full-functioned toolkit interface / environment. It is a set of chemical utilities (normalizations, data conversions, comparison functions) which provide the missing pieces required to manage chemical data in an Oracle database.
Design Goals:
The key design goals for this version haven't changed from those presented in previous discussions:
The one new design goal added to the equation is the following:
The main point here is that we recognize that in addition to the differences in the database itself (the servers, databases, tables, indexes), the members of the Oracle user community (the developers, database administrators, users) have very different perspectives than those which we are used to dealing with.
In order for the product to be successful, the Daylight cartridge must behave in a predictable, understandable way. The paradigms we use within our cartridge must match those which Oracle developers and DBAs already use and understand.
Architecture:
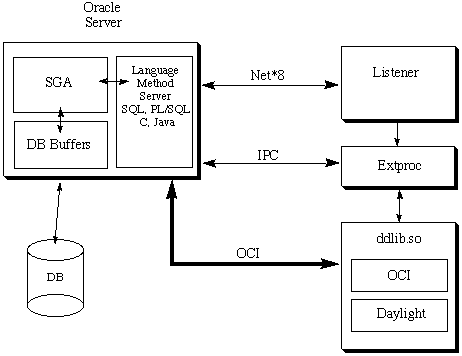
The Daylight toolkit interfaces with the Oracle server via callouts to the "extproc" utility. This utility provides a RPC-like mechanism for performing C-language function calls. Daylight toolkit code is wrapped inside this RPC layer for each of the defined cartridge functions.
One of the first concerns about this architecture is the efficiency of the RPC mechanism, and the potential that extproc will be a performance bottleneck. Some simple tests indicate that this isn't a problem. Consider the contrib program "cansmi", which takes as input SMILES and outputs canonical SMILES. A simple example, with 1999 SMILES from the medchem demo database runs rapidly:
$ time cansmi < test.smi CN(C)CCCN1c2ccccc2Sc3ccccc13 COc1ccc(OC)c(c1)C(O)C(C)NC(C)(C)C Nc1ccc(cc1)S(=O)(=O)Nc2nccs2 CCOC(=O)Nc1ccc(SCC2COC(Cn3ccnc3)(O2)c4ccc(Cl)cc4Cl)cc1 Cn1c(=O)n(C)c2ncn(CC(O)CN3CCN(CCCSc4ccccc4)CC3)c2c1=O Cn1cnc2n(C)c(=O)[nH]c(=O)c12 ... SMILES in: 1999; SMILES out: 1999; SMILES changed: 0 So long, baby! real 0m2.82s user 0m2.78s sys 0m0.03s
The analogous test can be run using the Oracle Cartridge by creating a table of the same 1999 SMILES, and running a SQL query:
SQL> describe cansmidemo;
Name Null? Type
-------------------- ------- ----------------------------
ID NUMBER
SMILES VARCHAR2(4000)
SQL> select count(1) from cansmidemo;
COUNT(1)
----------
1999
SQL> select smi2cansmi(smiles, 0) from cansmidemo;
CN(C)CCCN1c2ccccc2Sc3ccccc13
COc1ccc(OC)c(c1)C(O)C(C)NC(C)(C)C
Nc1ccc(cc1)S(=O)(=O)Nc2nccs2
CCOC(=O)Nc1ccc(SCC2COC(Cn3ccnc3)(O2)c4ccc(Cl)cc4Cl)cc1
Cn1c(=O)n(C)c2ncn(CC(O)CN3CCN(CCCSc4ccccc4)CC3)c2c1=O
Cn1cnc2n(C)c(=O)[nH]c(=O)c12
...
1999 rows selected.
Elapsed: 00:00:03.80
As it turns out, a significant portion of the time spent is performing output to the screen. In order to eliminate that time, we'll rerun the queries as follows:
$ time cansmi < test.smi | wc
SMILES in: 1999; SMILES out: 1999; SMILES changed: 0
So long, baby!
1999 1999 74725
real 0m2.80s
user 0m2.74s
sys 0m0.03s
And with Oracle:
SQL> select sum(length(smi2cansmi(smiles, 0))) from cansmidemo;
SUM(LENGTH(SMI2CANSMI(SMILES,0)))
---------------------------------
72725
Elapsed: 00:00:02.95
The overhead of executing functions through the extproc utility is roughly 250 ms in this case. This represents approximately 5000 - 10000 round-trips per second. For all but the most trivial toolkit processing, this will be a minor factor.
Another issue is data bandwidth between the extproc utility and the server. Tests on the blob-based index indicate that we can retrieve upwards of 100,000 rows per second from a tabular data source, and 60 MB per second from a blob-based data source.
Each of these data throughput and round-trip limits represents a design constraint which must be considered in the overall cartridge design. The design described in this whitepaper is what we consider to be the optimum tradeoff between resource efficiency, search performance, and the ability to maintain the full transaction concurrency model within Oracle for all cartridge data.
Cartridge Specification:
As indicated earlier, an Oracle Cartridge typically consists of three sets of functionalities: object type definitions, packaged functions, and indexing / data access tools. In turn, each of these three areas will be discussed with respect to the Daylight cartridge implementation.
Object Types:
The daylight cartridge does not define any new Oracle object types!!!
| Daylight Object | External Language |
|---|---|
| molecule | SMILES |
| reaction | SMILES |
| pattern | SMARTS |
| transform | SMIRKS |
| fingerprint | Encoded ASCII |
| depiction | 2D coordinate list |
| conformation | 3D coordinate list |
| datatree | TDT |
| monomer | Monomer SMILES |
| multimer | CHUCKLES |
| varimer | CHORTLES |
| varipattern | CHARTS |
Note that our external languages are all very expressive and well-behaved. That is, they are compact, with high information density. They are all printable ASCII strings. They all have well defined syntax and semantics.
When needed, the cartridge instantiates internal Daylight objects within the cartridge to perform a specific task (eg. calculate a molecular weight from a SMILES). The interfaces between Oracle and Daylight always pass objects as their external string representations.
Implications of this "Object Model":
Since our objects are represented as strings within the RDBMS, any Oracle, Informix, Sybase, JDBC, ODBC, CORBA, etc., etc., etc., client, server, middleware, application layer, etc., etc., etc. can handle these "objects" in their external form.
Only the endpoints of communication must understand what the objects mean: the Daylight Oracle cartridge provides the server-side endpoint, and a front end user interface provides the client-side endpoint. Otherwise, the objects effectively "tunnel" through the middle layers.
This does not preclude the design of an Oracle-specific object layer on top of the cartridge system (eg. ODBC); we simply don't require one, and don't dictate which model, if any, you use.
There is an overhead associated with instantiating objects on demand. Naturally, the functions which are provided in the cartridge perform higher granularity operations than in the native Daylight toolkit.
For example, consider the SQL operator smi2cansmi(). It's data dictionary definitions follow:
create or replace function fsmi2cansmi( smiles in VARCHAR2, type in number )
return varchar2
is
language C
name "oci_smi2cansmi"
library DDLIB
with context
parameters ( context,
smiles STRING,
smiles LENGTH INT,
smiles INDICATOR,
type,
type INDICATOR,
RETURN );
create or replace operator smi2cansmi binding (varchar2, number)
return varchar2 using fsmi2cansmi;
The cartridge C code which implements the function looks a lot like regular toolkit code, with the notable addition of a bunch of 'OCI' calls.
char *oci_smi2cansmi(OCIExtProcContext *context,
char *smi, int slen, short smi_ind,
OCINumber *ocitype, short type_ind)
{
OCIEnv *envhp;
OCISvcCtx *svchp;
OCIError *errhp;
char *retval;
dt_Handle ob;
int lens, type;
char *str;
/*** Deal with arguments ***/
...
ob = dt_smilin(slen, smi);
str = dt_cansmiles(&slen, ob, type);
if ((ob != NULL_OB) && (str != NULL) && (slen > 0))
{
retval = (char *)OCIExtProcAllocCallMemory(context, slen);
strncpy(retval, str, slen);
retval[slen] = '\0';
}
else
{
retval = (char *)OCIExtProcAllocCallMemory(context, 4);
*retval = '\0';
}
dt_dealloc(ob);
return retval;
}
The important points to recognize are that the function takes a SMILES string as input, and returns a SMILES string as output. Inside the function, it creates an internal molecule or reaction object from the SMILES, canonicalizes it, and then destroys the internal molecule or reaction object before returning. The internal Daylight object only exists for the duration of the call. The function is stateless with respect to the Daylight toolkit.
Although there is some additional overhead for instantiating objects and throwing them away, this must be weighed against the cost of performing the extproc call, the overhead of performing the IPC for the call, and the overhead of providing state information (if one were to attempt to implement persistant objects within extproc). The additional overhead has minimal impact on overall throughput.
Furthermore, there are very real opportunities for optimizations and shortcuts which we can exploit at the string level. For example, caching the most recent calculation can benefit queries like:
select id, smi2cansmi(smiles, 0) from table
order by length(smi2cansmi(smiles, 0)) asc;
Similarly, some operations can be performed without actually interpreting the external representation of the object. For example, it is simple to parse a SMILES lexically and count the net charge.
There are quite a few user-accessible PL/SQL functions, SQL operators, and extensible indexes for the cartridge. The complete list.
Extensible Indexes:
The the major change in implementation is the implementation of indexes. In version 08 and before, all index operations were implemented in a single blob-based index. We now split the indexes up into four distinct indextypes. The reasons for this change are:
The main advantage of the ddexact indextype is that it can index strings up to 4000 bytes (the maximum varchar2 length), while the internal BTree can only index strings up to approximately 40% of a block; for a database with a 2048 byte blocksize, this means that the largest indexable varchar2 string using the BTree is approximately 700 bytes. Similarly, in a future version of the cartridge this index will support the comparison of LOB datatypes; the BTree index does not.
This index requires approximately 22 bytes per row, independent of the length of the SMILES being indexed.
SQL> select * from medium where exact(smiles, 'Oc1ccccc1') = 1;
ID SMILES
-------- ----------------------------------------
220688 Oc1ccccc1
Elapsed: 00:00:00.10
This index requires approximately 30 bytes per row, independent of the length of the SMILES being indexed.
SQL> select * from medium where graph(smiles, 'Oc1ccccc1') = 1;
ID SMILES
-------- ----------------------------------------
153175 O=C1CCC=CC1
181024 O=C1CCCC=C1
220688 Oc1ccccc1
247340 O=C1C=CCC=C1
320108 OC1=CC=CC[CH]1
332013 Oc1c[c]ccc1
332014 Oc1cc[c]cc1
333710 Oc1[c]cccc1
347378 O=C1CC[CH]C=C1
360322 O=C1[CH]C=CC=C1
443810 [O-]C1CCCCC1
486637 O=C1CCC[C]=C1
568426 OC1CC=CC=C1
740390 [OH2+]C1CCCCC1
14 rows selected.
Elapsed: 00:00:00.36
This index requires approximately 22 bytes per component, independent of the length of the SMILES being indexed.
SQL> select * from rxn where reactant(smiles, 'Oc1ccccc1') = 1;
ID SMILES
-------- ------------------------------------------------------
1914882 CC1Sc2ccccc2N(C)C1=O.Oc1ccccc1>>CN1C(=O)C(C)(Sc2ccccc1
2)c3ccc(O)cc3
319303 CN(C)P1OCc2ccccc12.Oc1ccccc1>>C1OP(Oc2ccccc2)c3ccccc13
...
122 rows selected.
Elapsed: 00:00:00.32
SQL> select count(1) from medium where contains(smiles, 'O=c1ccocc1') = 1;
COUNT(1)
----------
6126
Elapsed: 00:00:20.87
SQL> select * from rxn where contains(smiles, '>>O=c1c(C)cocc1') = 1;
ID SMILES
-------- ----------------------------------------
2009323 CCOC(=O)C.CC(C)(C)[Si](C)(C)OC(=O)C(F)(F
)F.O=Cc1coc2ccccc2c1=O>>CCOC(=O)CC(O[Si]
(C)(C)C(C)(C)C)c1coc2ccccc2c1=O
291327 CCOC(=O)CC(=O)c1ccccc1.Fc1ccccc1C(=O)Cl>
>CCOC(=O)c1c(oc2ccccc2c1=O)c3ccccc3
...
111 rows selected.
Elapsed: 00:00:01.20
SQL> select count(1) from medium where tanimoto(smiles, 'OC(=O)CS') > 0.8;
COUNT(1)
----------
19
Elapsed: 00:00:13.82
SQL> select smiles, tanimoto(smiles, 'OC(=O)CS') from medium
where tanimoto(smiles, 'OC(=O)CS') > 0.8;
SMILES SCORE(1)
---------------------------------------- ----------
OCC(S)C=O .800000012
[NH4+].[O-]C(=O)CS .918918908
[Na+].[O-]C(=O)CS .894736826
COC(=O)CS .871794879
O.O.O.[Ca+2].[O-]C(=O)C[S-] .894736826
[Ca+2].[O-]C(=O)C[S-] .894736826
NCCO.OC(=O)CS .809523821
[K+].[O-]C(=O)CS .944444418
CCSCC(=O)O .809523821
[Ca+2].[O-]C(=O)CS .894736826
[Na+].[Bi+2].[O-]C(=O)C[S-] .809523821
SMILES SCORE(1)
---------------------------------------- ----------
[Sr+2].[O-]C(=O)CS .894736826
CCOC(=O)CS .809523821
CSCC(=O)O .871794879
C[S+](C)CC(=O)O .850000024
CCOC(=O)C[S] .809523821
[As].COC(=O)C[S].COC(=O)C[S].COC(=O)C[S] .809523821
CC(S)C(=O)[O-] .871794879
[Ba+2].[O-]C(=O)CS.[O-]C(=O)CS .894736826
19 rows selected.
Elapsed: 00:00:13.70
Additional Search Times:
The following table lists some additional comparative search times for the blob-based indexes. The databases are:
The timings are on a Sun Ultra 60 (2x330MHz), with 768 MB of real memory. The Oracle installation is a vanilla 8.1.5 install, with the only changes being the increase of db_block_buffers, log_buffers parameters from default values in init.ora. All database and program files reside on a single disk partition (no RAID). All transactions use full rollback (size of rollback segments was increased from default values), but not archivelog.
| Table name | Index type | Column | Creation time (hh:mm:ss) |
|---|---|---|---|
| small | smiles | exact | 2:02 |
| small | smiles | graph | 6:50 |
| small | smiles | blob | 11:47* |
| small | fingerprint | blob | 00:57 |
| savant_smi | smiles | exact | 22:01 |
| savant_smi | smiles | graph | 1:12:59 |
| savant_smi | smiles | blob | 2:07:00* |
| savant_smi | fingerprint | blob | 5:26 |
| large | smiles | exact | 1:55:56 |
| large | smiles | graph | 7:24:00 |
| large | smiles | blob | 11:16:30* |
| rxn | smiles | exact | 1:44 |
| rxn | smiles | role | 14:21 |
| rxn | smiles | blob | 20:34* |
| rxn | fingerprint | blob | 00:47 |
Query Performance:
| Table name | Query | Hits | Time (mm:ss) |
|---|---|---|---|
| small | exact(smiles, 'c1ccccc1') = 1 | 1 | 00:00.07 |
| small | graph(smiles, 'c1ccccc1') = 1 | 3 | 00:00.07 |
| small | contains(smiles, 'OC(=O)C1') = 1 | 0 (invalid query) | 00:00.02 |
| small | contains(smiles, 'OC(=O)CS') = 1 | 492 | 00:01.48 |
| small | matches(smiles, '[OH]C(=O)CS') = 1 | 268 | 00:01.39 |
| small | fingertest(smiles, 'OC(=O)CS') = 1 | 1147 | 00:00.54 |
| small | fingertest(fp, 'OC(=O)CS') = 1 | 1147 | 00:00.43 |
| small | tanimoto(smiles, 'OC(=O)CS') > 0.8 | 7 | 00:00.95 |
| small | tanimoto(fp, 'OC(=O)CS') > 0.8 | 7 | 00:00.94 |
| small | tversky(smiles, 'OC(=O)CS', 0.5, 0.5) > 0.8 | 33 | 00:01.50 |
| small | tversky(fp, 'OC(=O)CS', 0.5, 0.5) > 0.8 | 33 | 00:01.35 |
| savant_smi | exact(smi, 'Oc1ccccc1') = 1 | 15 | 00:00.10 |
| savant_smi | graph(smi, 'Oc1ccccc1') = 1 | 51 | 00:00.26 |
| savant_smi | contains(smi, 'O1C(=O)CCS1') = 1 | 2 | 00:04 |
| savant_smi | matches(smi, '[OH]C(=O)CS') = 1 | 2260 | 00:14 |
| savant_smi | tanimoto(smi, 'OC(=O)CS') > 0.8 | 6 | 00:05 |
| savant_smi | tanimoto(fp, 'OC(=O)CCS') > 0.8 | 24 | 00:04 |
| large | exact(smiles, 'NCCc1ccccc1') = 1 | 1 | 00:00.36 |
| large | graph(smiles, 'c1ccccc1') = 1 | 28 | 00:00.50 |
| large | contains(smiles, 'NCCc1ccc(S)cc1') = 1 | 2617 | 00:59** |
| rxn | reactant(smiles, 'Sc1ccccc1') = 1 | 122 | 00:01.45 |
| rxn | product(smiles, 'Oc1ccccc1') = 1 | 13 | 00:00.15 |
| rxn | contains(smiles, 'OC(=O)CS') = 1 | 1154 | 00:00.13 |
| rxn | contains(smiles, '>>OC(=O)CS') = 1 | 754 | 00:06 |
| rxn | contains(smiles, '>>OC(=O)CS') = 1 | 793 | 00:12 |
| rxn | matches(smiles, '>>[OH]C(=O)CS') = 1 | 167 | 00:06 |
| rxn | tanimoto(smiles, 'OC(=O)CCl>>OC(=O)CS') > 0.5 | 68 | 00:01.05 |
Summary:
To summarize, we can deliver a set of Oracle utilities via a cartridge which will provide high performance chemical information processing within the Oracle system. These tools allows the handling of molecules and reactions, complete with coordinates for display and fingerprints for searching efficiency. Four chemistry-specific indextypes are provided, which allow the database creator to tailor the database for specific searches and applications.
To Do:
These are several outstanding issues which I haven't covered in the above:
Timetable:
The cartridge is in beta now. Please contact us for availability information. This release will be supported on Solaris 2.7. Other platforms (SGI, Linux) will be made available in the next 3 - 6 months.
Futures:
Oracle indicated that version 8.1.6 will be available in production RSN (real soon now). One of the important new features in 8.1.6 is the ability to run Java in the server. This will impact the design for future versions of the Daylight cartridge, specifically the design of the blob-based indexes.
Informix has been "back-burnered". Note that all of the various interfaces and tools described here have direct parallels within the Informix Datablade model. It is possible to provide an Informix datablade; this will be dictated by demand.
How about:
select clogp('c1ccccc1') from dual;
CLOGP('C1CCCCC1')
-----------------
2.142
Elapsed: 00:00:00.02
Program objects can be called from extproc. It is feasible to provide an extensible interface through program objects which doesn't require any user extproc programming.
One last possibility down the road. Consider the implications of the following PL/SQL code, which runs under 8.1.5.. The first section is a simple PL/SQL program. The second is a user-defined function which takes a molecule or reaction object handle as an argument.
declare
subtype dt_Handle is number;
mol dt_Handle;
dummy number;
ismiles varchar2(4000);
begin
ismiles := 'Oc1ccccc1';
mol := dt_smilin( ismiles );
dbms_output.put_line('Proton count for ' ||
ismiles || ' is ' || proton_count(mol));
dummy := dt_dealloc(mol);
ismiles := 'OC1CCCCC1';
mol := dt_smilin( ismiles );
dbms_output.put_line('Proton count for ' ||
ismiles || ' is ' || proton_count(mol));
dummy := dt_dealloc(mol);
end;
create or replace function proton_count (ob in number)
return number as
subtype dt_Handle is number;
atoms dt_Handle;
atom dt_Handle;
hcount number := 0;
begin
atoms := dt_stream(ob, 19);
loop
atom := dt_next(atoms);
if (atom = 0) then
exit;
end if;
if (dt_number(atom) = 1) then
hcount := hcount + 1;
end if;
hcount := hcount + dt_imp_hcount(atom);
end loop;
return hcount;
end;
OUTPUT:
Proton count for Oc1ccccc1 is 6
Proton count for OC1CCCCC1 is 12
It is possible for Daylight to provide a general PL/SQL toolkit interface within Oracle, including Smiles, Smarts, Fingerprint, Depict, Reaction, Monomer, and Program object but maybe not Thor or Merlin. Issues to be resolved include memory management, memory persistance and multiprocessing within extproc. We must understand Oracles long-term plans for extproc before proceeding. Of course, more than just a novelty, work on this product will be dictated by customer demand.