
Jack Delany
Introduction / Definitions:
It will be useful starting out to provide some definitions and discussion about exactly what a multithreading toolkit is, and why it is worthwhile to develop. First, consider a process. A process is a collection of resources dedicated to the execution of a single task (program) in the computer. It includes some computational ability (a CPU), memory, and access to the I/O facilities. All of these resources are allocated to the process in a uniform way, defined by the operating system.

Processes typically don't know anything about the rest of the computer, including other processes. There are mechanisms for processes to communicate with one another (SYSV IPC, network I/O, parent-child streams), however these are fairly expensive because these communications are mediated by the operating system itself.
Processes historically have been defined to include a single CPU as the sole computational engine (a single 'thread of execution'). Hence, if one wanted to write a program which made use of multiple CPUs, one would have to break that program up into multiple processes and incur the overhead of communication between those processes.
The multithreading ideas basically says that we no longer limit a process to a single thread of execution. Each process may have multiple computations occurring at any given time. These 'threads of execution' can be started, stopped, added, and deleted at will.
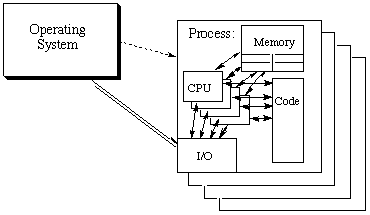
This is a very powerful idea and provides several advantages:
The Goal:
To modify the Daylight Toolkit so that it will run efficiently in a multithreading environment. The multithreading interface must not substantially change the current external toolkit interface and must cause a minimal negative impact on performance of current toolkit programs.
Driving Forces:
The following recent developments and longer term Daylight development goals all impact our plans for the Daylight Toolkit, and have provided the impetus for us to tackle this project:
If one writes a Java program which uses the Daylight Toolkit, one must serialize all the toolkit calls. They need not run in a single thread, but there may not be multiple toolkit functions executing in parallel.
Sadly, concurrency is not the only issue between Java/JNI and Daylight; there are several other issues being investigated (garbage collection, memory leaks, memory conflicts).
Pthreads are relevant now because they give us a set of cross-platform tools for internal use in this project. It is important to note that pthreads were added to Solaris in Version 2.5, and to IRIX in Version 6.0. This will be a consideration when choosing the supported platforms for our version 4.7x.
Much of the overhead and complexity of the process/search management of Merlinserver can simply go away under a full multithreading environment. This will give us the opportunity to move forward with new Merlinserver development ideas with a streamlined, more manageable server.
Data Issues:
In order to understand the issues around delivering a multithreading toolkit, we must look at the types of memory available within a process and how the toolkit uses it. There are three types of memory available within a process:
[Note: These issues and types of data are generally relevant for the toolkit programmer designing his own application using the toolkit]
Now, consider some specific cases of the above data classes which are used within the toolkit. First, there are two classes of static data: 'read-only' static data and 'toolkit global' static data (my terms).
Toolkit objects are made up of data which is allocated from the heap at runtime. The responsibility for protecting objects from simultaneous access by multiple threads will fall on the toolkit programmer, using the dt_mp_lock() / dt_mp_unlock() utilities. The big question to be resolved for object access is the granularity of the accesses to the objects (see below).
Automatic data is used for local processing and isn't a concern since is is thread-local.
I/O Issues:
I/O streams are global resources. Hence, they must also be managed carefully in a multithreaded environment. Fortunately, the Daylight Toolkit was designed to do minimal I/O. The areas of concern are:
So far, we haven't explicitly dealt with either of these issues. I'll talk more about them in a bit.
Toolkit Granularity:
The basic internal data structure of the toolkit is as follows:
At the lowest level, there are a small number of global variables. These point to a hierarchy of heap data. The globals include a struct which contains information about the handle-to-pointer table, a pointer to the head of the vector binding list, and a struct which points to the error queue.

Each object is a struct which may point to additional heap data, including data which is not owned by it (for example, each bond struct has pointer to the two atom structs that it connects). Modification of one object can result in modifications to other objects. [The arrows in blue represent this class of reference between objects].
Since the toolkit is implemented using an opaque interface, internal behaviors of toolkit functions are not rigorously defined. Only external behaviors are well defined. This is a very pleasant model for the developers; we are free to use lazy evaluation, to organize internal data however we choose, and to change these internal data organizations at will.
dt_Handle mol;
dt_Handle dep;
void *do_dep(void *arg)
{
dep = dt_alloc_depiction(mol);
dt_calcxy(dep);
thr_exit(NULL);
}
main()
{
pthread_t thr;
void *rc;
dt_String smi;
dt_Integer len;
mol = dt_smilin(3, "NCC");
pthread_create(&thr, NULL, do_dep, NULL);
smi = dt_cansmiles(&len, mol, 0);
pthread_join(thr, &rc);
...
}
The unfortunate side effect of this opaque interface is that we can't
generally describe the results of a given modification of one object. A
seemingly simple modification to an object may have far-reaching impacts upon
other data structures within the toolkit. In the above example, what if
the dt_cansmiles() function, during its processing, modifies the internal
state of the molecule object. Furthermore, what if the dt_calcxy() code
uses this internal state. This example would potentially cause corruption
of the molecule object and the depiction object.
Given that the key to a multithreaded library implementation is the control of the scope of data access and modifications, this leads to a problem. The solution to this problem is simply to define the allowed concurrency at a larger granularity than otherwise possible.
The granularity of the multiprocessing directly impacts the overall performance of a multithreaded program. Consider the following trivial example:
struct {
int a;
int b;
int c;
} sd;
Assume that the variables sd.a, sd.b and sd.c are modified independently by
the various running threads. Any given variable may be read and modified by
one thread at a time; hence it is necessary to protect the read/write steps
for each variable. There are two solutions: 1) provide a mutex around the
entire shared_data structure and 2) provide a mutex around each data item
within the structure.
struct {
pthread_mutex_t mut;
int a;
int b;
int c;
} sd;
Each thread, before modifying any variable, must obtain the mutex. This
is the simplest to code. It is possible that threads performing
unrelated functions will collide with one-another and contend for the
same mutex. This organization will unnecessarily slow the overall
throughput.
struct {
pthread_mutex_t mut_a;
int a;
pthread_mutex_t mut_b;
int b;
pthread_mutex_t mut_c;
int c;
} sd;
Each thread, before modifying a variable, must obtain the mutex for that
variable. This is more complex to code, but should provide the best
performance because there will be less contention for the various
resources between threads.
The first example has coarser granularity of its data access than the second. Using the above simple examples, it seems beneficial to performance to always provide the finest granularity of access to the data structures. This is not necessarily true. In the above example, what if sd.a and sd.b are sometimes modified together. For example, if sd.a is a certain value, then both sd.a and sd.b are changed. In this case, two mutexes must be obtained before the modification can take place. If not properly designed, deadlock may result. Similarly, if this dual modification occurs a large percentage of the time, the overall performance of the second example may be slower than the first.
There is no 'right' answer for the level of granularity of access to the data which is optimal. The tradeoffs include:
granularity: coarse <------------> fine code complexity: less <------------> more synchronization overhead: less <------------> more resource contention: more <------------> less overall throughput: ????
Unfortunately, the overall throughput depends on the specific application and data access patterns. Our goal is to deliver a generally useful multithreading interface. It will not be possible to deliver an optimal interface, however we'll run a set of test applications to verify the overall performance.
So, what is the best level of granularity of concurrency within the Daylight toolkit? The level which makes sense at this stage of the project is at the object family level. By object family, we mean objects which are related to one-another as parent-child or base-derivatives. We propose to introduce the new concept of an 'object family' as part of the Daylight Toolkit programming model. This appears appropriate for objects like molecules and reactions (where we already have the concept of dt_mod_on() / dt_mod_off(), however, for Thor and Merlin, where the server object is the ultimate ancestor of all of the opened databases, datatrees, etc., this seems heavy handed.
Another confounding factor is functions which depend on multiple objects (eg. dt_match()). These functions will require exclusive access to all object families referenced in their argument list to be guaranteed safe. With dt_match(), for example, both the pattern and the target (molecule or reaction) are accessed and potentially modified during a dt_match() operation. Hence, only exclusive access to both object families will suffice.
I believe that, on a case-by-case basis, we'll need to decide if we can support finer granularity than the object family. For example, in Thor, can each thread be a different server or database connection? Is sharing a single connection between threads, and requiring non-overlapping thor I/O's possible? Similar issues with Merlin. These answers are yet to be determined.
Proposed Interface:
The interface to support multithreading is lightweight. We only need to add functionality to support the locking of object families. All other multithreading functions will be transparent to the toolkit.
dt_mp_initialize(void) => dt_Boolean success
This function may not end up in the final interface. We're still investigating whether or not it will be required. If the impact on non-multithreaded programs is minimal, we'll leave it out.
dt_ancestor(dt_Handle ob) => dt_Handle ob
dt_mp_lock(dt_Handle ob) => dt_Boolean success
dt_mp_unlock(dt_Handle ob) => dt_Boolean success
dt_mp_trylock(dt_Handle ob) => dt_Boolean success
Internally, these functions are a thin wrapper around a mutex (MUTual EXclusion) which is attached to the dt_ancestor() of the object.
Nothing prevents a programmer from misusing threads, or from accessing the same object from multiple threads. Only if the programmer always gets a lock for the object family before modification can he be guaranteed to have exclusive access to the object. If one or more threads does not obey this convention, then the program may not be thread-safe.
Alternately, if the programmer understands the data access of the program and designs the application appropriately, one can forgo locking and achieve very good throughput.
Toolkit objects are shared between threads; if needed, any thread can access any object in the toolkit. If, in any given application, the objects are not actually shared, then locking is not required. The examples at the end will illustrate these points.
Thread Safety vs. Reentrancy:
Reentrancy is simply the ability for a function to call itself. In terms of multi-threading programming, it is a test for proper internal data access. That is, a reentrant function doesn't maintain or modify any global state data during its operation. There are many operations which cannot be made reentrant because they necessarily modify global data (or interact with external I/O streams, which are considered global resources).
For these functions, one must protect the shared resources. Once these shared resources are protected from multiple simultaneous accesses, then a function can be considered 'thread-safe'. This means that multiple simultaneous threads can access the function.
The toolkit will be reentrant, not thread-safe. As part of the interface we will provide the guidelines and tools needed to write thread-safe programs, however it will be the responsibility of the programmer to do so. We can implement a heavy-handed thread-safe toolkit interface with simple wrappers around the toolkit. We'll probably include this in 4.7x just for yucks...
dp_xxx(ob)
{
dt_mp_lock(ob);
rc = dt_xxx(ob);
dt_mp_unlock(ob);
return rc;
}
Example programs:
Lets look at some example applications. First, these will help illustrate some of the program models and tradeoffs which come into play when writing multithreaded programs. Second, these will be useful to test the overall throughput and limitations of the toolkit when running multithreaded applications.
These examples will be part of contrib in 4.7x, as a tutorial to illustrate MT programming with the toolkit.
Additional Issues:
Internal Initialization:
There are several places where we initialize tables of data (the internal periodic table, fingerprint bit counts), check licenses, and initialize the read-only objects (isohydro, depiction-hydrogens). There are several approaches to handling these in a multi-threading environment.
First, there is the pthread_once() facility in pthreads. This allows you to define threads which execute once, when needed, to initialize data. The main disadvantage to this mechanism is that one uses threads, and incurs some overhead, every time you hit one of these initializers; even for a non-multithreaded program.
Next, one can explicitly initialize data. This can be done either prior to running multiple threads, or after. Initialization prior to starting multiple threads is much easier to support, and incurs NO overhead for non-multithreaded programs. This is the proposed solution.
System Calls:
There are quite a few standard system calls in UNIX operating systems which were not designed to be reentrant. They either keep internal global state information (eg. strtok()) or return pointers to static data (gethostbyname()).
The man pages for system calls will say whether or not a particular system call is reentrant, and if not, what to do about it. Typically, UNIX vendors have implemented reentrant versions of the problem system calls. The reentrant versions have "_r" appended to their names (strtok_r(), gethostbyname_r()).
Thread Cancelation:
Thread cancellation is an issue which we'll need to address. Basically, one can send a message to kill a thread, and there are certain system and pthread calls which will be interrupted. Optionally, one can disable this cancellation mechanism for the internals of the toolkit, and only allow cancellation when outside of the toolkit. The other choice would be for the toolkit not to worry about it, and have the programmer responsible for deciding if it is OK for a thread to be canceled from within the toolkit.
The big potential problem here is the possibility that the toolkit will be left in a corrupt state after a thread cancellation. If, for example, a thread gets cancelled during a network I/O to a merlinserver, how do we guarantee that the toolkit cleans up after itself so the remaining threads don't get confused.
Signal Handling:
This is a similar issue to thread cancellation, with the difference that we have a precedent for signal handling already. With the current toolkit, and process-level signals, we basically say that the toolkit does no signal handling, and it is the programmers responsibility to set up the signal handlers and decide which signals to be caught/ignored/etc. With pthreads, signals have a thread-level granularity, and we need to decide the best way to handle them.
Summary:
We will be able to provide a reentrant toolkit in 4.7x. It will be useful for development of multithreading programs. Many common applications will benefit greatly from the use of multiple threads, as the concurrency model of the toolkit will match up well with typical toolkit program usage.
There are still outstanding issues to be addressed: the Thor and Merlin client toolkit and their I/O functionalities, thread cancellation, and signal handling. These will be addressed for the 4.7x release, however these should not significantly change the model as presented here.