
Daylight Chemistry Database Cartridge
Oracle8i Implementation Overview
Sam DeFazio, Cathy Trezza
Oracle Corporation
New England Development Center
Nashua, NH 03062
sdefazio@us.oracle.com
ctrezza@us.oracle.com
| NAME VARCHAR2(100) | SMILES VARCHAR2(4000) |
|
|
|
|
|
| HASH BLOB | REFRESH_NUMBER NUMBER |
The index data is stored in an ancillary index table. This table contains a couple of columns. One is a Binary Large Object, also known as a BLOB (shown as HASH here). This column contains the index structure used in any queries. The second column is called REFRESH_NUMBER, and is used for caching the index (which is discussed below). This table contains exactly one row.
DML Methods
Query Operator Methods
create or replace type SmilesIndexIM as object
(
-- Query context/state
db_loc RAW(8),
lob_loc RAW(8),
-- DDL Methods
member function ODCIGetInterfaces(...),
member function ODCIIndexCreate(...),
member function ODCIIndexDrop(...),
-- DML Methods
ODCIIndexInsert (...) return number,
member function ODCIIndexDelete (...) return number,
member function ODCIIndexUpdate (...) return number,
-- Query Operator Methods
-- IndexStart method for Contains
member function ODCIIndexStart(..., strt number,
stop number,
cmpval varchar2)
return number,
-- IndexStart method for SIMILAR
member function ODCIIndexStart(..., strt number,
stop number,
cmpval varchar2,
threshold float)
return number,
member function ODCIIndexFetch(nrows number,
rids OUT
sys.odciridlist)
return number,
member function ODCIIndexClose return number
)
create or replace indextype SmilesIndex
for
Contains(VARCHAR2,VARCHAR2),
LookFor(VARCHAR2,VARCHAR2),
Tautomers(VARCHAR2,VARCHAR2),
Matches(VARCHAR2,VARCHAR2),
Similar(VARCHAR2,VARCHAR2,FLOAT),
Nearest(VARCHAR2,VARCHAR2,INTEGER)
using SmilesIndexIM ;
-- Create sample table of compounds
create table Compound
(ID number,
Name varchar2(256),
Smiles varchar2(4000) ...
);
-- Create index on smiles column
create index on Compound(Smiles)
INDENXTYPE IS SmilesIndex ... ;
-- Perform similarity query and return score
select Score(1)
from Compound
where Similar(Smiles, 'S=PS', .1, 1)=1;
-- Select compounds similar to given structure
select Name, Smiles
from Compound
where Contains(Smiles, 'CN(C)CCCN')=1;
-- Select the nearest 10 compounds to given structure
select Score(1)
from Compound
where Nearest(Smiles, 'S=PS', 10)=1;

The start, fetch, and close methods of a query operator run in a separate external process, called extproc. There is one external process per session. The external process is separate from the database process, and CAN NOT bring down the server in the event of a program error in the index. The data from the buffer cache is passed to the external process via standard OCI requests to read the data from the BLOB. This data is stored in memory and passed to the Dayblob interface to process the query. The results of the query are the ROWIDs which are then passed back to the database along with any ancillary information, such as score.
The index itself can be large. A 1 million compound table would have an index table that is about 136M, and the entire amount could be allocated for each session using the index. To deal with this issue, we recommend session multiplexing, discussed below.
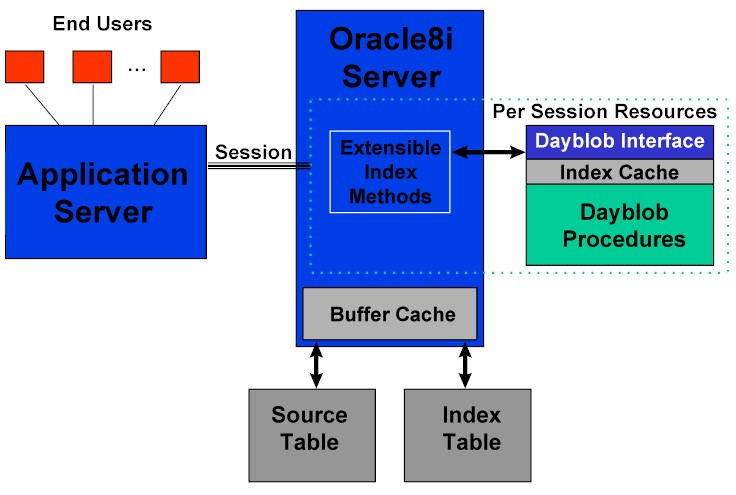
Common queries run in a short period of time, so the best way to deal with this problem is to place an application tier between the user and the database and multiplex the requests to the available sessions in the database. This allows you to process all the queries but keep a handle on the memory usage on the server.
Caching is turned on and off via a procedure call and is under the user's control. The cache is automatically reloaded when a change occurs to the index. This synchronization is handled by a sequence number in the index table (REFRESH_NUMBER) and the sequence number of a package holding the memory for the index. When these numbers match, the memory is in synch with the table. When these numbers differ, such as when a transaction is commited in this or another session, the two numbers will be different and the index is marked to be reloaded at the start of the next query.
