
Database-oriented synthesis discovery and planning tools generally use some form of "retrosynthetic" approach, i.e., iteratively working backwards from the desired product through reactions to reagents. This forms a retrosynthetic tree of this form:
Problems associated with discovering useful synthetic paths with this approach include: evaluating relative merit (e.g., "in-stock" vs. "in-catalog" vs. "in-literature"), discovering paths through "near hits" (rather than exact matches) and managing data in a very large tree so enough levels can be processed to find all optimal paths. Most currently available systems don't attempt to solve these problems but rather present one or a few tree-levels at a time which is pruned by an expert user. The resultant synthesis-planning programs require highly-trained users and are neither well-used nor well-loved by bench chemists.
The retrosynthetic problem is strikingly similar to the chess-playing problem: both are basically a search for an optimal path though a very large, relatively low-connectivity multitree. Much work has gone into the chess-playing problem over the last 30 years. The results (compared to human players) are that applying simple optimization methods such as alpha/beta mini/max to intuitively-derived merit functions don't work well, artificially "clever" tactical and strategical programs don't do much better, but using brute force with simplistic methods is is very effective (e.g., Deep Thought). A chess-playing program that exhaustively checks 3-5 moves ahead can be beat by a "B" player; the same program checking 6-10 moves ahead can beat a grandmaster. Extant retrosynthetic programs were designed around disk-based (10 mS) access of relatively small databases (1e4 to 3e5 reactions). Current capabilities allow memory-based (100 nS) access of large databases (3e6 reactions). This suggests the following experiment: if we increase the depth (speed), and breadth (size) of retrosynthetic search to current standards, do we get an enormously more usable synthetic search engine? We should be able to answer this question with current Daylight tools, e.g., a fully-cached SpresiReact Thor database (2.1e10 reactions) running on a Sun 4000 (a few RAM GB's and a few CPU GIPS).
Most synthetic path discovery tasks are not addressed well by exact-matching retrosynthetic programs. A more powerful approach would be to build an general search engine which operates on the graph formed by all known reactions.
For example, consider the key reactions (i.e., ignoring stoichiometry, conditions and agents) of 8 molecules (labeled A to G in order of decreasing heat of formation):

This data can be organized as a graph with molecules as nodes and reactions as edges:

Many synthetic planning issues are illustrated even in this tiny graph. Consider the problem of finding reaction pathways which transform A to E:
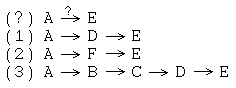
If we just consider these 8 molecules and optimize the number of steps, paths (1) and (2) are both optimal (2 steps) and (3) is suboptimal (4 steps). All other things being equal, reaction paths with fewer steps are are better than those with more steps. However, "all other things" are almost never "equal" and the "number of steps" is often a better informatics metric than a practical one. A short schema like (2) might be impractical because it requires special conditions if you don't happen to have the appropriate equipment (e.g., the reaction is done in a high-temperature, high-pressure corrosive "bomb" environment). A long schema like (4) might be more practical, especially if some of the reactions are easy (e.g., spontaneous decomposition).
Another issue is that the "right answer" depends on the end-use of the information. The requirements of small-scale experimental bench chemists, combinatorial chemists and production chemists are quite different. For instance, production chemists looking for large-scale methods would want to know about the reaction E-to-A and examine the possiblilty of an economically viable reaction reversal.
We are currently thinking about building a synthesis search engine which optimizes paths based on a user-specified function. Factors which we are considering so far are:
It appears that Thor will form the basis for the retrosynthetic search engine and Merlin for the generalized reaction graph server. The nature of the user interfaces are as yet unclear, but we assume that they will be delivered to a web-based environment. User feedback is very important on this project and this year is the time to do it!