
Jack Delany
Introduction:
This whitepaper/presentation will describe Oracle Cartridge technology, the current Daylight/Oracle cartridge, and our current development and future plans for the cartridge.
Oracle Cartridge Technology:
An Oracle Data Cartridge is a bundled set of tools which extends Oracle clients and servers with new capabilities. Typically, a single data cartridge deals with a particular 'information domain'. Some examples of current data cartridges include: image processing, spatial processing, audio processing.
A cartridge consists of a number of different components which work together to provide complete database capabilities within the information domain. The components include:
A cartridge extends the server. The new capabilites are tightly integrated with the database engine. The Cartridge interface specification provides interfaces to the query parser, optimizer, indexing engine, etc. Each of these subsystems of the server learns about the cartridge capabilities through these interfaces. The cartridge can use SQL, PL/SQL, Java, C, etc. to implement the functions.
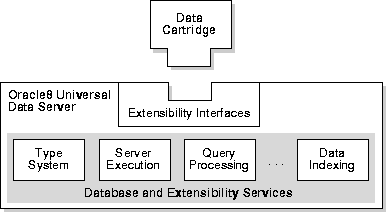
From Oracle's point of view, the cartridge idea allows third-party organizations to expand the capabilities of the Oracle database server in a modular, supportable fashion.
Design Goals:
The key design goals for the cartridge are:
The main point here is that we recognize that in addition to the differences in the database itself (the servers, databases, tables, indexes), the members of the Oracle user community (the developers, database administrators, users) have very different perspectives than those which we are used to dealing with.
In order for the product to be successful, the Daylight cartridge must behave in a predictable, understandable way. The paradigms we use within our cartridge must match those which Oracle developers and DBAs already use and understand.
So, what is the Daylight Cartridge? First, what it isn't. It isn't a full-functioned toolkit interface / environment. It is a set of chemical utilities (normalizations, data conversions, comparison functions) which provide the missing pieces required to manage chemical data in an Oracle database.
Architecture:

The Daylight toolkit interfaces with the Oracle server via callouts to the "extproc" utility. This utility provides a RPC-like mechanism for performing C-language function calls. Daylight toolkit code is wrapped inside this RPC layer for each of the defined cartridge functions.
One of the first concerns about this architecture is the efficiency of the RPC mechanism, and the potential that extproc will be a performance bottleneck. Some simple tests indicate that this isn't a problem. Consider the contrib program "cansmi", which takes as input SMILES and outputs canonical SMILES. A simple example, with 1999 SMILES from the medchem demo database runs rapidly:
$ time cansmi < test.smi CN(C)CCCN1c2ccccc2Sc3ccccc13 COc1ccc(OC)c(c1)C(O)C(C)NC(C)(C)C Nc1ccc(cc1)S(=O)(=O)Nc2nccs2 CCOC(=O)Nc1ccc(SCC2COC(Cn3ccnc3)(O2)c4ccc(Cl)cc4Cl)cc1 Cn1c(=O)n(C)c2ncn(CC(O)CN3CCN(CCCSc4ccccc4)CC3)c2c1=O Cn1cnc2n(C)c(=O)[nH]c(=O)c12 ... SMILES in: 1999; SMILES out: 1999; SMILES changed: 0 So long, baby! real 0m2.82s user 0m2.78s sys 0m0.03s
The analogous test can be run using the Oracle Cartridge by creating a table of the same 1999 SMILES, and running a SQL query:
SQL> describe cansmidemo;
Name Null? Type
-------------------- ------- ----------------------------
ID NUMBER
SMILES VARCHAR2(4000)
SQL> select count(1) from cansmidemo;
COUNT(1)
----------
1999
SQL> select smi2cansmi(smiles, 0) from cansmidemo;
CN(C)CCCN1c2ccccc2Sc3ccccc13
COc1ccc(OC)c(c1)C(O)C(C)NC(C)(C)C
Nc1ccc(cc1)S(=O)(=O)Nc2nccs2
CCOC(=O)Nc1ccc(SCC2COC(Cn3ccnc3)(O2)c4ccc(Cl)cc4Cl)cc1
Cn1c(=O)n(C)c2ncn(CC(O)CN3CCN(CCCSc4ccccc4)CC3)c2c1=O
Cn1cnc2n(C)c(=O)[nH]c(=O)c12
...
1999 rows selected.
Elapsed: 00:00:03.80
As it turns out, a significant portion of the time spent is performing output to the screen. In order to eliminate that time, we'll rerun the queries as follows:
$ time cansmi < test.smi | wc
SMILES in: 1999; SMILES out: 1999; SMILES changed: 0
So long, baby!
1999 1999 74725
real 0m2.80s
user 0m2.74s
sys 0m0.03s
And with Oracle:
SQL> select sum(length(smi2cansmi(smiles, 0))) from cansmidemo;
SUM(LENGTH(SMI2CANSMI(SMILES,0)))
---------------------------------
72725
Elapsed: 00:00:02.95
The overhead of executing functions through the extproc utility is roughly 250 ms in this case. This represents approximately 5000 - 10000 round-trips per second. For all but the most trivial toolkit processing, this will be a minor factor.
Another issue is data bandwidth between the extproc utility and the server. Tests on the blob-based index indicate that we can retrieve upwards of 100,000 rows per second from a tabular data source, and 60 MB per second from a blob-based data source.
Each of these data throughput and round-trip limits represents a design constraint which must be considered in the overall cartridge design. The design described in this whitepaper is what we consider to be the optimum tradeoff between resource efficiency, search performance, and the ability to maintain the full transaction concurrency model within Oracle for all cartridge data.
Cartridge Specification:
As indicated earlier, an Oracle Cartridge typically consists of three sets of functionalities: object type definitions, packaged functions, and indexing / data access tools. In turn, each of these three areas will be discussed with respect to the Daylight cartridge implementation.
Object Types:
The daylight cartridge does not define any new Oracle object types!!!
| Daylight Object | External Language |
|---|---|
| molecule | SMILES |
| reaction | SMILES |
| pattern | SMARTS |
| transform | SMIRKS |
| fingerprint | Encoded ASCII |
| depiction | 2D coordinate list |
| conformation | 3D coordinate list |
| datatree | TDT |
| monomer | Monomer SMILES |
| multimer | CHUCKLES |
| varimer | CHORTLES |
| varipattern | CHARTS |
Note that our external languages are all very expressive and well-behaved. That is, they are compact, with high information density. They are all printable ASCII strings. They all have well defined syntax and semantics.
When needed, the cartridge instantiates internal Daylight objects within the cartridge to perform a specific task (eg. calculate a molecular weight from a SMILES). The interfaces between Oracle and Daylight always pass objects as their external string representations.
Implications of this "Object Model":
Since our objects are represented as strings within the RDBMS, any Oracle, Informix, Sybase, JDBC, ODBC, CORBA, etc., etc., etc., client, server, middleware, application layer, etc., etc., etc. can handle these "objects" in their external form.
Only the endpoints of communication must understand what the objects mean: the Daylight Oracle cartridge provides the server-side endpoint, and a front end user interface provides the client-side endpoint. Otherwise, the objects effectively "tunnel" through the middle layers.
This does not preclude the design of an Oracle-specific object layer on top of the cartridge system (eg. ODBC); we simply don't require one, and don't dictate which model, if any, you use.
There is an overhead associated with instantiating objects on demand. Naturally, the functions which are provided in the cartridge perform higher granularity operations than in the native Daylight toolkit.
For example, consider the SQL operator smi2cansmi(). It's data dictionary definitions follow:
create or replace function fsmi2cansmi( smiles in VARCHAR2, type in number )
return varchar2
is
language C
name "oci_smi2cansmi"
library DDLIB
with context
parameters ( context,
smiles STRING,
smiles LENGTH INT,
smiles INDICATOR,
type,
type INDICATOR,
RETURN );
create or replace operator smi2cansmi binding (varchar2, number)
return varchar2 using fsmi2cansmi;
The cartridge C code which implements the function looks a lot like regular toolkit code, with the notable addition of a bunch of 'OCI' calls.
char *oci_smi2cansmi(OCIExtProcContext *context,
char *smi, int slen, short smi_ind,
OCINumber *ocitype, short type_ind)
{
OCIEnv *envhp;
OCISvcCtx *svchp;
OCIError *errhp;
char *retval;
dt_Handle ob;
int lens, type;
char *str;
/*** Deal with arguments ***/
...
ob = dt_smilin(slen, smi);
str = dt_cansmiles(&slen, ob, type);
if ((ob != NULL_OB) && (str != NULL) && (slen > 0))
{
retval = (char *)OCIExtProcAllocCallMemory(context, slen);
strncpy(retval, str, slen);
retval[slen] = '\0';
}
else
{
retval = (char *)OCIExtProcAllocCallMemory(context, 4);
*retval = '\0';
}
dt_dealloc(ob);
return retval;
}
The important points to recognize are that the function takes a SMILES string as input, and returns a SMILES string as output. Inside the function, it creates an internal molecule or reaction object from the SMILES, canonicalizes it, and then destroys the internal molecule or reaction object before returning. The internal Daylight object only exists for the duration of the call. The function is stateless with respect to the Daylight toolkit.
Although there is some additional overhead for instantiating objects and throwing them away, this must be weighed against the cost of performing the extproc call, the overhead of performing the IPC for the call, and the overhead of providing state information (if one were to attempt to implement persistant objects within extproc). The additional overhead has minimal impact on overall throughput.
Furthermore, there are very real opportunities for optimizations and shortcuts which we can exploit at the string level. For example, caching the most recent calculation can benefit queries like:
select id, smi2cansmi(smiles, 0) from table
order by length(smi2cansmi(smiles, 0)) asc;
Similarly, some operations can be performed without actually interpreting the external representation of the object. For example, it is simple to parse a SMILES lexically and count the net charge.
For discussion of the PL/SQL functions, SQL operators, and extensible indexes for the cartridge, see the official cartridge documentation.
Timing Tests:
The following table lists some comparative search times for the blob-based indexes. The databases are:
The tests are on three different machines: Red is a Sun Ultra 60 (2x360MHz), with 768 MB of real memory. Xmas is a Dell laptop (700MHz PentiumIII) with 512 MB memory, and green is a Origin 200 (2x270MHz R12000) with 2GB memory.
In all cases the Oracle installation is a vanilla 8.1.5 install, with the only changes being the increase of db_block_buffers and log_buffers parameters from default values in init.ora. All database and program files reside on a single disk partition (no RAID). All transactions use full rollback (size of rollback segments was increased from default values), but not archivelog.
| Index type | Column | red | xmas | green |
|---|---|---|---|---|
| nci | exact | 2:10 | 3:16 | 2:36 |
| nci | graph | 7:10 | 8:21 | 10:20 |
| nci | blob | 12:51* | 9:37* | 13:17* |
| rxn | exact | 1:44 | 2:46 | 2:12 |
| rxn | role | 14:21 | 34:51 | 25:05 |
| rxn | blob(smi) | 20:34* | 14:41* | 21:57* |
| rxn | blob(fp) | 00:47 | 01:47 | 01:03 |
| savant_smi | exact | 22:01 | 32:30 | 22:54 |
| savant_smi | graph | 1:12:59 | 1:25:08 | 1:33:38 |
| savant_smi | blob(smi) | 2:07:00* | 1:39:55* | 2:15:58* |
| savant_smi | blob(fp) | 5:26 | 12:18 | 7:07 |
| large | exact | 1:55:56 | ||
| large | graph | 7:24:00 | ||
| large | blob | 11:16:30* |
Query Performance (seconds elapsed):
| Table name | Query | Hits | Red | Xmas | Green |
|---|---|---|---|---|---|
| nci | exact(smi, 'c1ccccc1') = 1 | 1 | 0.07 | 0.12 | 0.12 |
| nci | graph(smi, 'c1ccccc1') = 1 | 3 | 0.17 | 0.17 | 0.21 |
| nci | contains(smi, 'OC(=O)C1') = 1 | 0 (invalid query) | 0.12 | 0.16 | 0.21 |
| nci | contains(smi, 'OC(=O)CS') = 1 | 507 | 1.48 | 1.83 | 2.03 |
| nci | matches(smi, '[OH]C(=O)CS') = 1 | 279 | 1.39 | 1.81 | 1.90 |
| nci | fingertest(smi, 'OC(=O)CS') = 1 | 1237 | 0.54 | 1.10 | 0.76 |
| nci | tanimoto(smi, 'OC(=O)CS') > 0.8 | 7 | 0.81 | 1.15 | 0.84 |
| nci | tversky(smi, 'OC(=O)CS', 0.5, 0.5) > 0.8 | 56 | 0.80 | 1.26 | 0.87 |
| rxn | reactant(smiles, 'Sc1ccccc1') = 1 | 282 | 1.45 | 4.30 | 0.83 |
| rxn | product(smiles, 'Oc1ccccc1') = 1 | 13 | 0.15 | 1.51 | 0.14 |
| rxn | contains(smiles, 'OC(=O)CS') = 1 | 1136 | 9.2 | 6.8 | 11.4 |
| rxn | contains(smiles, '>>OC(=O)CS') = 1 | 739 | 4.3 | 3.9 | 5.6 |
| rxn | contains(smiles, 'OC(=O)CS>>') = 1 | 782 | 8.2 | 6.6 | 10.5 |
| rxn | matches(smiles, '>>[OH]C(=O)CS') = 1 | 117 | 3.8 | 3.6 | 5.1 |
| rxn | tanimoto(smiles, 'OC(=O)CCl>>OC(=O)CS') > 0.5 | 68 | 0.60 | 1.24 | 0.92 |
| savant_smi | exact(smi, 'Oc1ccccc1') = 1 | 15 | 0.10 | 0.38 | 0.09 |
| savant_smi | graph(smi, 'Oc1ccccc1') = 1 | 51 | 0.16 | 0.61 | 0.15 |
| savant_smi | contains(smi, 'O1C(=O)CCS1') = 1 | 2 | 4.0 | 8.9 | 8.9 |
| savant_smi | matches(smi, '[OH]C(=O)CS') = 1 | 1575 | 14.0 | 19.7 | 28.3 |
| savant_smi | tanimoto(smi, 'OC(=O)CS') > 0.8 | 7 | 5.0 | 9.6 | 9.6 |
| savant_smi | tanimoto(fp, 'OC(=O)CCS') > 0.8 | 24 | 4.0 | 4.3 | 4.4 |
| savant_smi | fingertest(fp, 'OC(=O)CCS') = 1 | 18620 | 4.0 | 4.4 | 4.9 |
| large | exact(smiles, 'NCCc1ccccc1') = 1 | 1 | 36 | ||
| large | graph(smiles, 'c1ccccc1') = 1 | 28 | 50 | ||
| large | contains(smiles, 'NCCc1ccc(S)cc1') = 1 | 2617 | 59** |
Summary / Futures:
To summarize, we can deliver a set of Oracle utilities via a cartridge which will provide high performance chemical information processing within the Oracle system. These tools allows the handling of molecules and reactions, complete with coordinates for display and fingerprints for searching efficiency. Four chemistry-specific indextypes are provided, which allow the database creator to tailor the database for specific searches and applications.
Timetable:
The cartridge for Solaris is available as part of 4.71 now. The SGI and Linux versions are available as betas now. Target release date for the SGI and Linux versions is Q4, 2000.
Will likely be able to support the standard edition of 8i on all platforms. Longer term, parallelization and partitioned indexes may cause us to revise this position.
Ongoing work / minor enhancements:
| Query | Hits | Daycart (4.71) | Daycart (4.72) | Merlin (4.71) |
|---|---|---|---|---|
| contains(smi, '[Au]') = 1 | 16 | 0.53 | 0.45 | 0.18 |
| contains(smi, 'N#CN=CN') = 1 | 12 | 0.42 | 0.41 | 0.10 |
| contains(smi, 'OC(=O)CS') = 1 | 492 | 1.42 | 1.10 | 0.70 |
| matches(smi, '[OH]C(=O)CS') = 1 | 268 | 1.34 | 1.07 | 0.62 |
| tanimoto(smi, 'OC(=O)CS') > 0.75 | 20 | 0.52 | 0.49 | 0.06 |
| contains(smi, 'NCCc1cc(O)c(O)cc1') = 1 | 732 | 1.77 | 1.24 | 0.84 |
| tanimoto(smi, 'NCCc1cc(O)c(O)cc1') > 0.75 | 13 | 0.60 | 0.60 | 0.09 |
| contains(smi, 'C1CC1') = 1 | 828 | 8.3 | 4.8 | 7.8 |
| contains(smi, 'Cl') = 1 | 18590 | 10.7 | 9.1 | 8.8 |
| contains(smi, 'NC=O') = 1 | 24443 | 17.7 | 14.0 | 13.6 |
| contains(smi, 'OC=O') = 1 | 30396 | 21.8 | 17.3 | 17.1 |
Futures:
Oracle has announced version 8iR3. In addition to the capability (present from 8iR2) to run Java in the server, it will include the capability to compile server-side java to native code (JVM Accelerator). This opens up the design options for future versions of the blob-based indexes for the cartridge.
Similarly, one of the architectural changes we're considering is maintaining the blob-based index data in partly sorted order. This will allow us to minimize the I/O overhead during queries (at the cost of index creation overhead). Some prototyping has been completed. Consider the query:
select count(1) from savant_smi where tanimoto(fp, 'NCCc1ccccc1') > 0.9;
With the current 4.71 version, this query takes 2.38 seconds to search 1.1 million rows and return 15 hits. Under the prototype version, this query takes 0.17 seconds. Even more critical is that we can reduce the IPC and disk I/O by more than 90%.